01
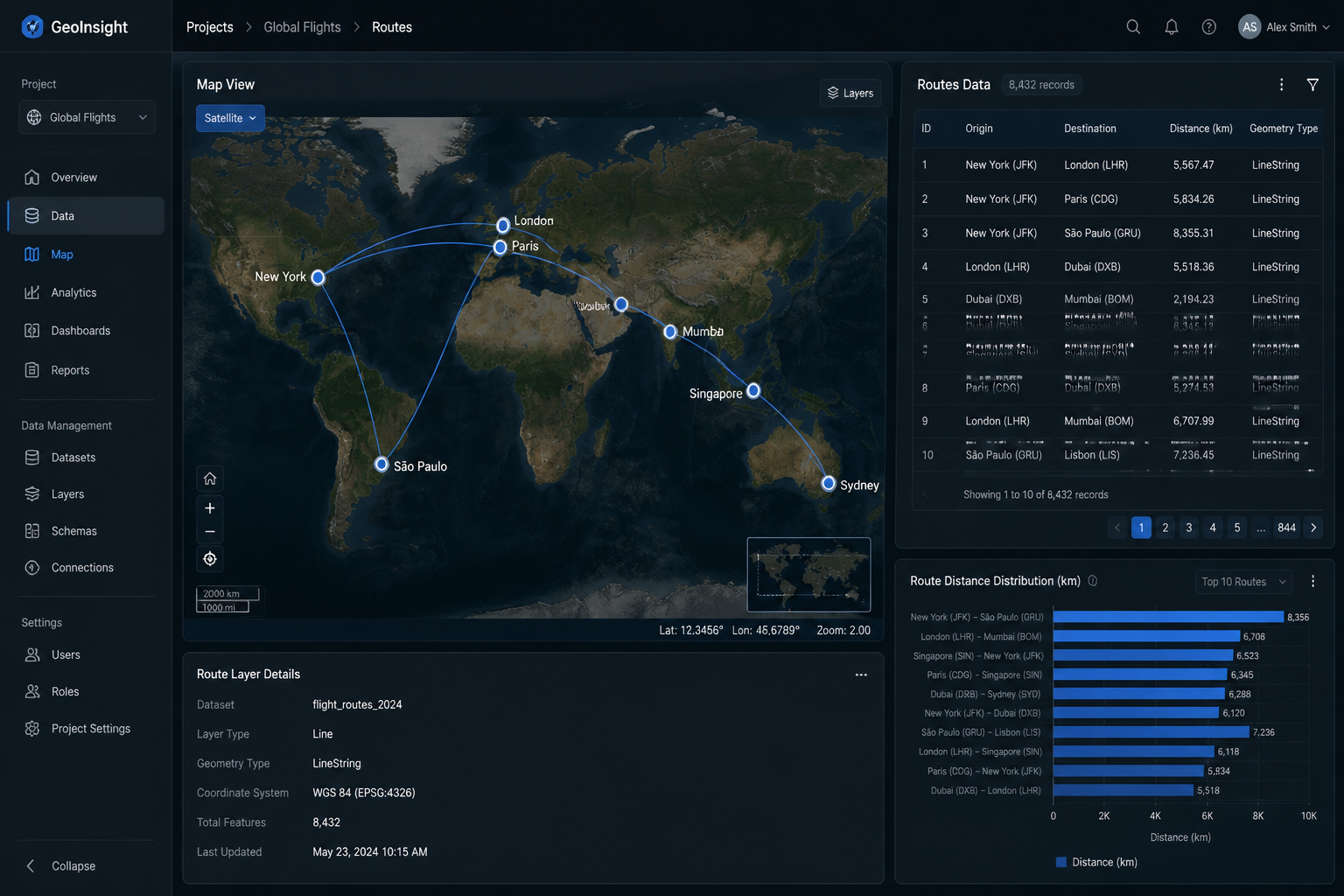
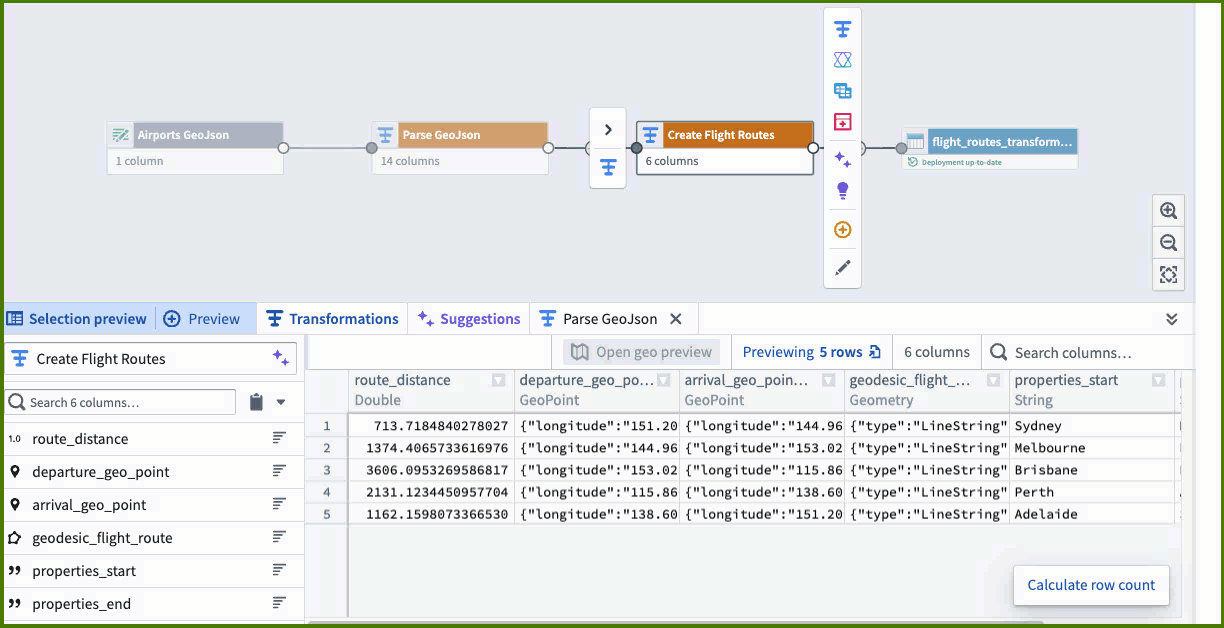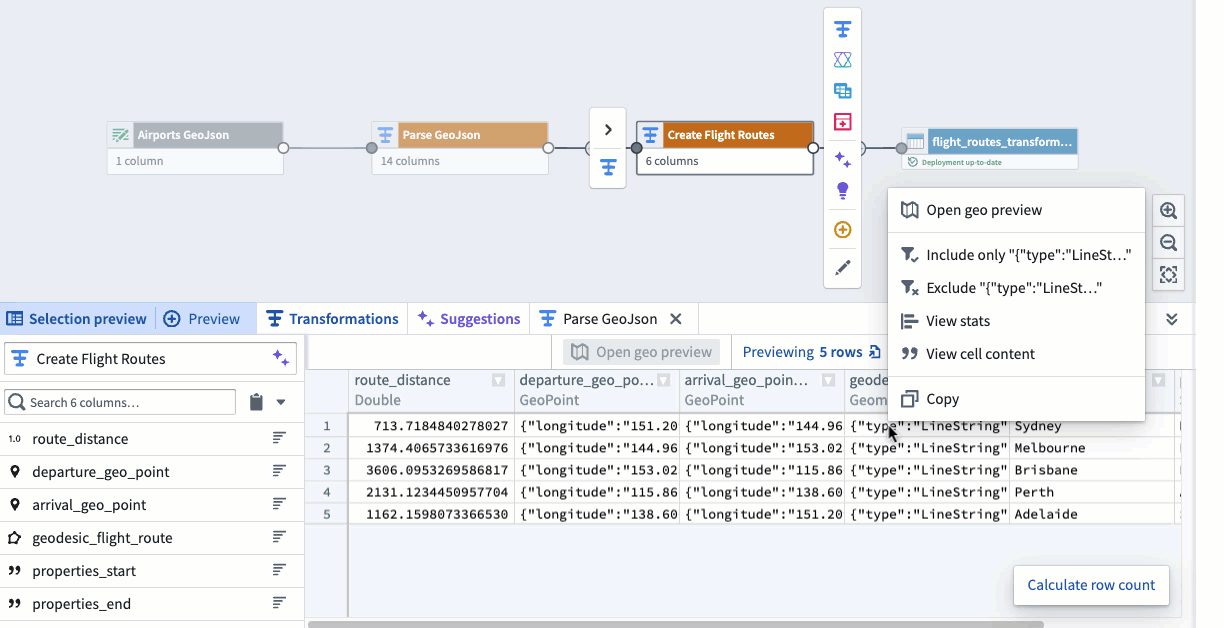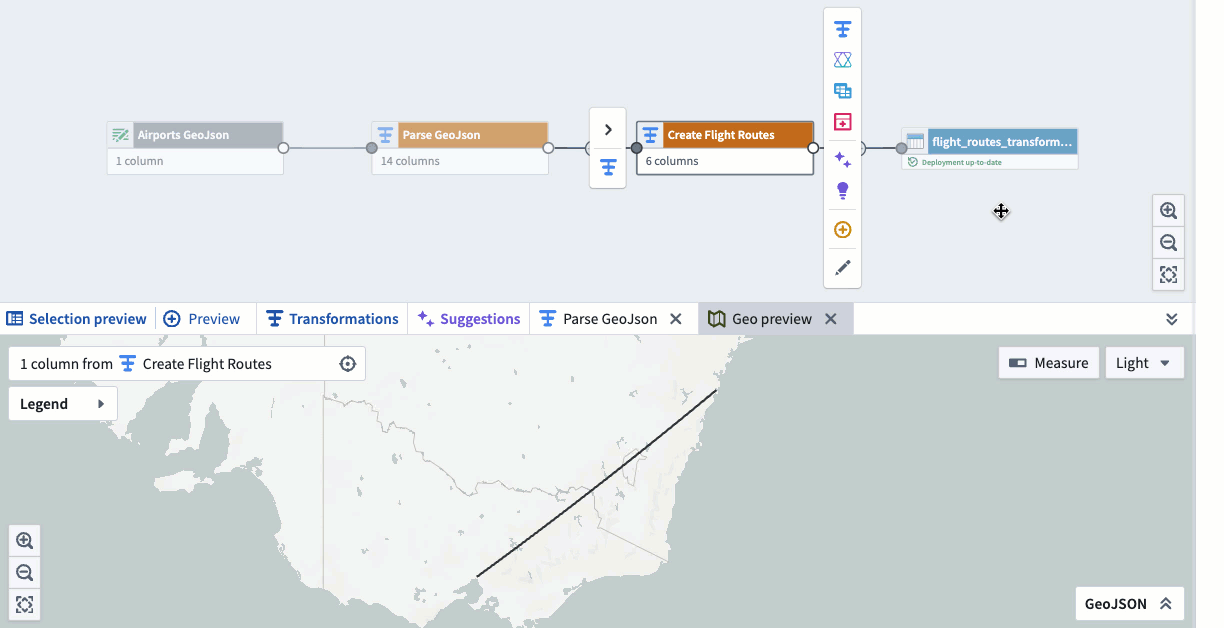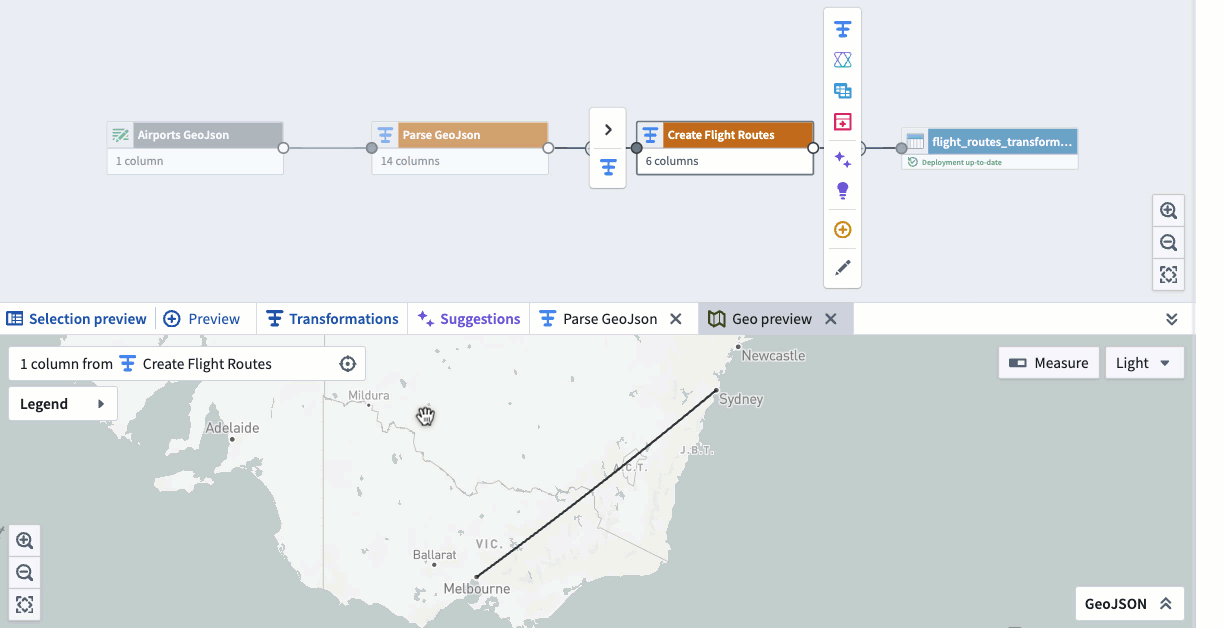
Three disconnected surfaces — notebook, parser, and BI tool — with no shared context
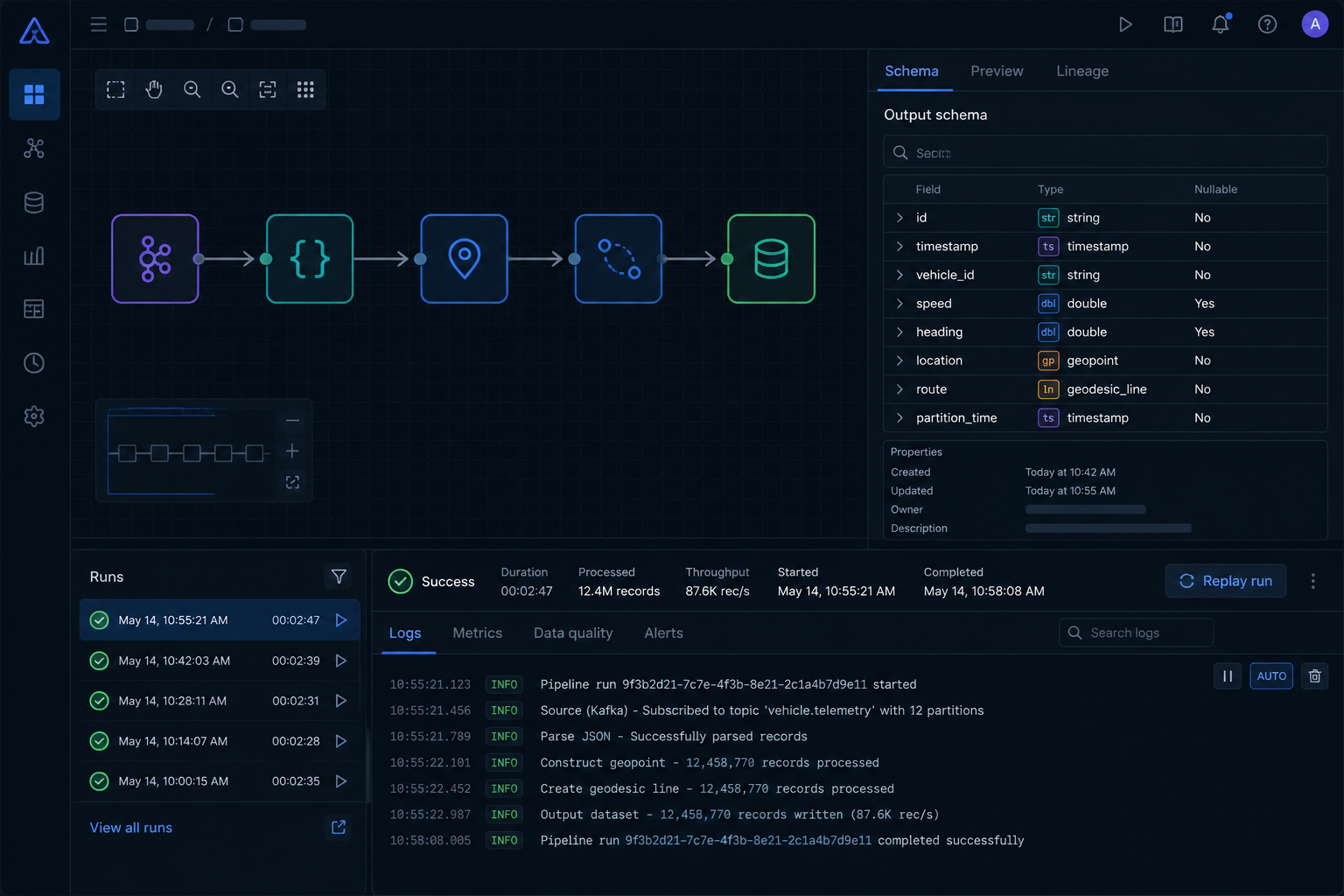
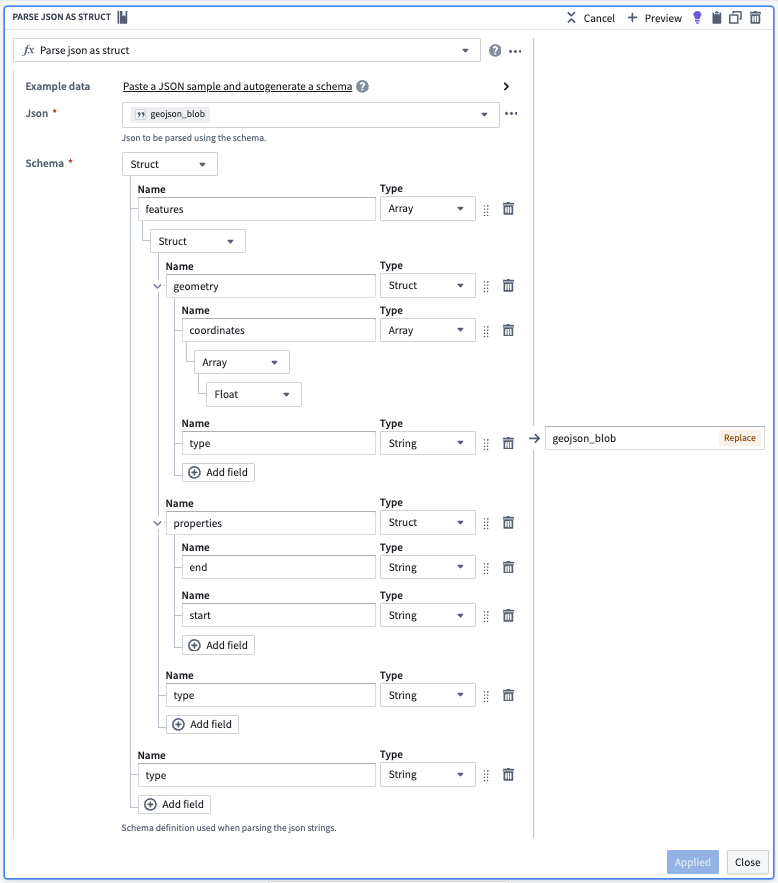
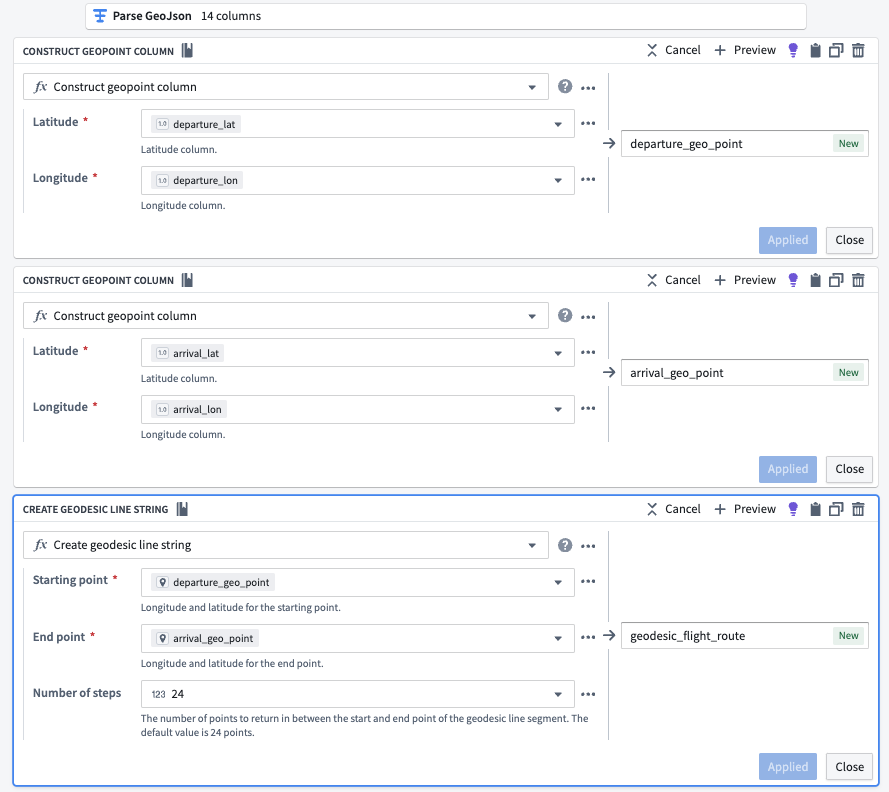
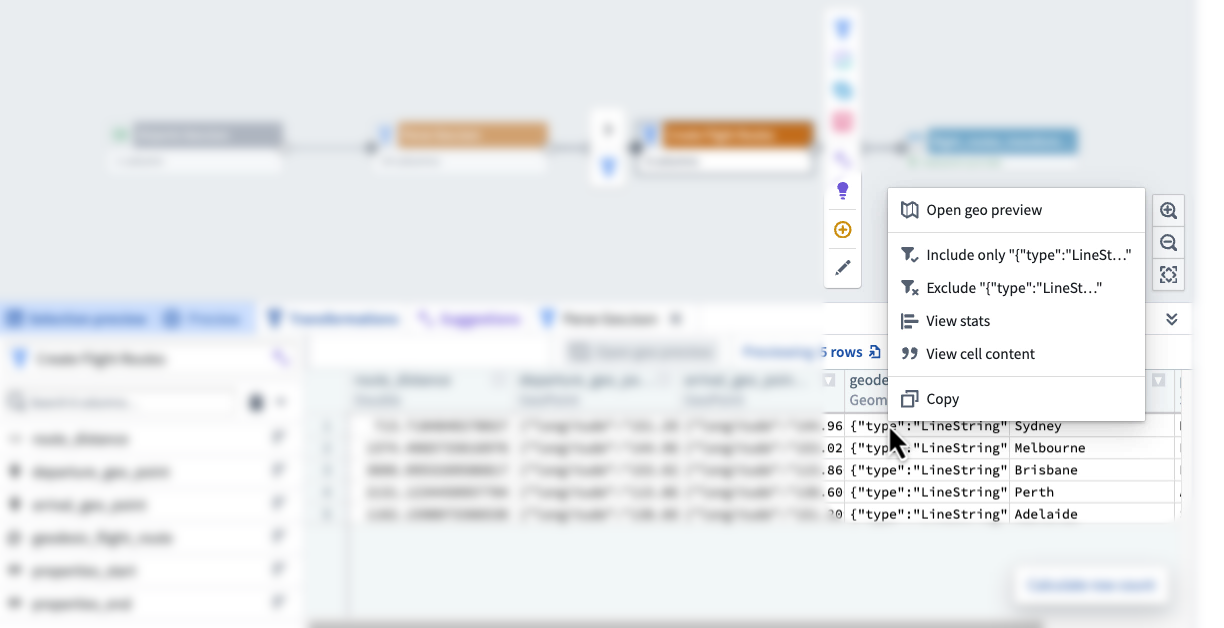
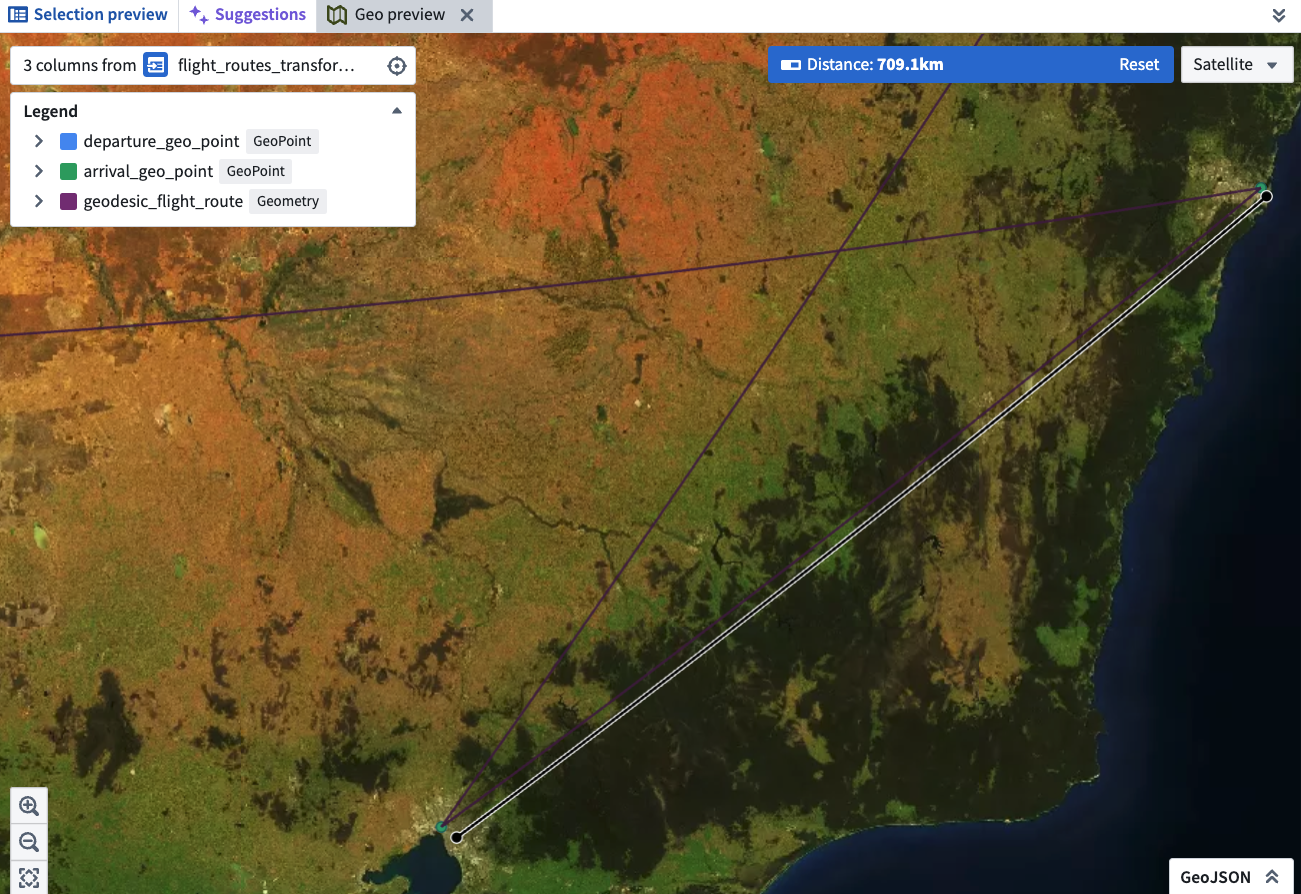
How we overcame it: Collapsed into one canvas where parsing, transformation and preview live together. A single viewport holds the pipeline graph, schema inspector and geo preview — no tab switching.